Columna escrita por Adriana Villa-Murillo, Dra. en Estadística y Optimización por la Universidad Politécnica de Valencia (UPV – España), académica de la Universidad Viña del Mar.
El 20 de febrero del 2010, la comisión de Estadística de la Organización de Naciones Unidas (ONU) sugirió designar al 20 de octubre como el día mundial de la Estadística; dado el importante rol de esta área de la matemática en decisiones de carácter gubernamental en pro del desarrollo sostenible de los países. Bajo tal premisa, el 3 de junio del mismo año, la comisión general designó oficialmente el primer día Mundial de la Estadística (Resolución 64/267) y, en el 2015, es cuando el mismo ente fija al 20 de octubre como el día Mundial de la Estadística a celebrarse quinquenalmente (Resolución 96/282).
A la fecha solo se han celebrado 3 años formalmente, pero lo resaltante es la importancia que con el pasar de los años se le está dando a la Estadística. Lo anterior, lo podemos evidenciar cronológicamente mediante los lemas dados en cada quinquenio:
- 2010: Celebración de los numerosos logros de las estadísticas oficiales.
- 2015: Mejores datos, mejores vidas.
- 2020: Conectando el mundo con datos en los que podemos confiar.
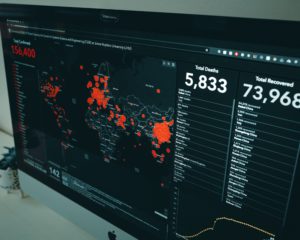
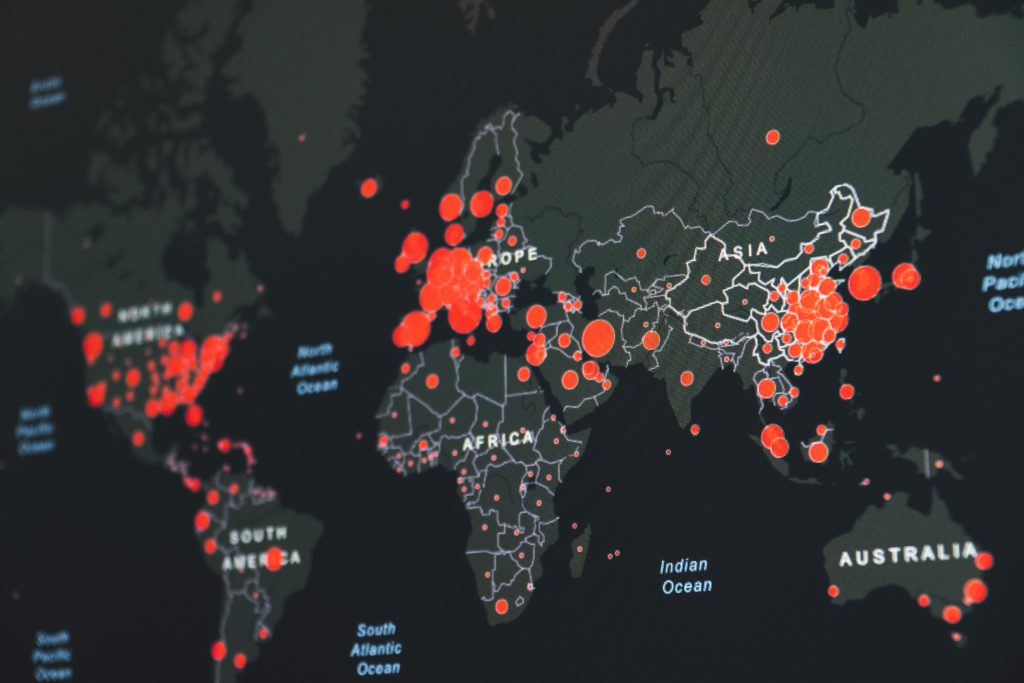
Quiero resaltar el último punto: “datos en los que podemos confiar”. Hay que recordar que el 2020 fue un año marcado por la pandemia y los reportes estadísticos oficiales tomaron un mayor auge a nivel mundial en la toma de decisiones. El presente escrito no pretende aunar en el tema de la pandemia, sino que reflexionemos un poco en la tan nombrada “Ciencia de datos” (Data Science) que cada día gana más popularidad en todos los ámbitos sociales.
La RAE (Real academia española) define a la ciencia como el conjunto de conocimientos obtenidos mediante la observación y el razonamiento, los cuales serán sistemáticamente estructurados con leyes y principios que darán capacidad predictiva, pudiendo ser éstos comprobables de forma experimental. Entonces, como primera reflexión o ejercicio, plantéese unir tal terminología a lo que ud. conoce como “datos”.
Por otro lado, se dice que la materia prima de la Estadística son los datos y eso, en líneas generales, es verdad. Para hacer menos complejo este escrito, cito la definición simple que da la misma RAE a la Estadística como una “rama de la matemática que utiliza grandes conjuntos de datos numéricos para obtener inferencias basadas en el cálculo de probabilidades”. Todos los que trabajamos en el área de la Estadística sabemos que lo de “datos numéricos” es relativo, pero no nos detengamos ahí, sigamos nuestra reflexión, pero ahora uniendo las dos palabras claves: “ciencia” y “datos”.
Teniendo en cuenta que los datos son, a grandes rasgos, la información concreta de un evento o suceso, entonces, es ilógico concebir la Ciencia de Datos sin la Estadística como columna vertebral. Es precisamente en este punto donde quiero aunar para que todos los que hacemos ciencia de datos recordemos la gran responsabilidad que esto conlleva y, para los que se están iniciando o quieran iniciar, entiendan que trabajar en Ciencia de Datos no es “procesar algoritmos a ver qué sale”.
La figura 1, mediante interpretaciones de conjuntos, nos permite visualizar mejor la complejidad del tema. La Ciencia de Datos se sustenta en 3 áreas fundamentales (conjuntos en la figura): en primer lugar, el análisis estadístico como un proceso artístico que combina eficientemente teoremas y procesos matemáticos que dan firmeza y rigurosidad a la modelización y, por ende, a la estimación probabilística propuesta (Estadística matemática). Por su parte, las Ciencias informáticas serán las responsables de reproducir y hacer las iteraciones necesarias de los algoritmos insertos en el modelo propuesto. Y, finalmente pero no menos importante, se encuentra el conocimiento del área específica de estudio, que permita dar sentido común al modelo propuesto, es decir, el conocimiento previo de las variables bajo estudio en el contexto real.
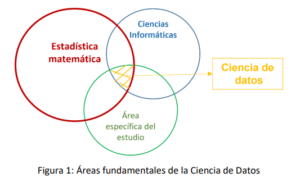
Abusando un poco de la teoría clásica de conjuntos, el punto resaltante en la figura es la diferencia de tamaños que presentan las áreas mencionadas. Esto se debe a que las leyes y principios que permitirán dar capacidad predictiva a los modelos propuestos en la Ciencia de Datos tiene sus cimientos en la Estadística. De aquí que se concibe a la modelización estadística como la combinación de elementos matemáticos con un ligero espacio para la incertidumbre, es decir, la estadística permite medir la probabilidad del error, no el error propiamente dicho. Todo lo anterior es lo que permite llamar a la Ciencia de Datos una verdadera ciencia (metódica y rigurosa) y no una simple reproducción informática de algoritmos prediseñados.
Lo anterior podría llevarnos a subestimar las otras áreas que aportan a la Ciencia de Datos que, si bien no son la base, es innegable el aporte importante en cada análisis. Para aunar en ello, pensemos en el esquema básico que plantea la Estadística clásica: donde cualquier análisis comienza con una depuración del conjunto de datos mediante herramientas de estadística descriptiva, seguidamente, el proceso inferencial donde se construyen modelos en términos de las posibles relaciones de las variables bajo estudio, para finalmente, validar los modelos propuestos mediante métricas que permitan medir el grado de incertidumbre del modelo propuesto.
Ahora bien, cuando se habla de Ciencia de Datos, se dota a cada una de esas fases de herramientas más complejas que permiten el manejo de grandes volúmenes de datos y el ajuste de heurísticas y metaheurísticas que conlleven a medir los niveles de asociación y/o relación entre variables; incorporándose así el concepto de Optimización Estadística. Todo lo anterior se formaliza con la llegada de subdisciplinas como el Data Mining (Minería de datos), el Big Data (análisis de grandes bases de datos) y el Machine Learning (aprendizaje automatizado), cada una con características y objetivos bien marcados, pero no excluyentes entre sí; sin dejar a un lado la rigurosidad y formalismo matemático. En la mayoría de los casos se combinan tales conceptos mediante algoritmos exhaustivos y con iteraciones definidas en cada fase, y es justamente aquí donde las ciencias informáticas hacen su aporte en combinación con los conceptos fundamentales de las variables bajo estudio que darán, finalmente, una respuesta lógica al problema inicial.
Entonces, todo lo expuesto (sin entrar mucho en detalles teóricos para no hacer pesado el presente escrito) nos conlleva nuevamente a la pregunta inicial: ¿Es la Ciencia de Datos una disciplina real o una moda? Como estadístico puedo pensar en la moda como una medida de tendencia central, o coloquialmente “el valor que más se repite” y, si consideramos que día a día todos los ámbitos sociales requieren analistas de datos para dar respuestas oportunas a sus problemáticas: entonces sí, la Ciencia de Datos se puede considerar una moda. Pero, por otro lado, me inclino más a llamarla como una disciplina, pues como en todo proceso científico existe la reproducción y evolución, es decir, se necesita una constante preparación y actualización académica que permita potenciar de forma robusta los modelos predictivos propuestos.